
重点
文章想要对预训练的模型也进行微调,比如BEATs,ATST,所以模型的结构并非是重点,微调方式是重点
模型结构
模型结构如图所示:
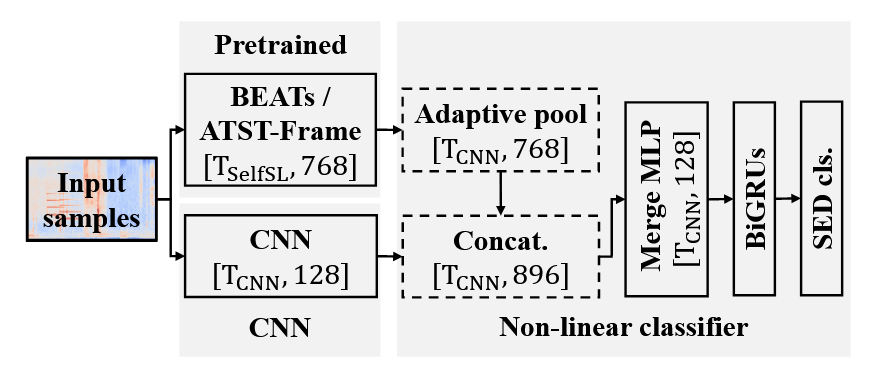
微调方法
文章提出两阶段来微调一个由RCNN和BEATs(或ATST等预训练模型,都行)构成的融合模型的方法。第一阶段,是正常的训练,冻结BEATs,训练RCNN,同时计算强标签(来自于训练数据)的损失与伪标签(来自于上一轮模型的预测)的损失,然后对模型进行更新,这个时候得到临时的模型参数(看作学生模型),然后拿出上一轮模型的参数和本轮的临时模型参数进行EMA,得到本轮最终的模型(看作教师模型,用于给出下一轮要用的伪标签)。在第二阶段,进行微调,仍然采用上一阶段的教师学生模型的思路,不同的是解冻所有参数,且此时减小强标签损失的权重,极大增加(2=>70)伪标签权重,还引入一致性训练损失(对频谱图拉伸压缩,插值)。
简单总结两个收获
(1)使用EMA更新参数,在之前读ATST论文里,也用到了EMA,可以防止在伪标签数据下,模型学不到有意义的表示,而是找到了一种简单恒等的方式来最小化损失函数。
(2)通过伪标签与无监督损失来利用未标注数据。作者还给了一个发现,就是帧级的ATST微调后带来的提升相比于补丁级的BEATs提升更大,这可能是由于它更好与SED这种帧级任务对齐。