这是一篇利用prompt思路优化USS(通用音频分离)任务的文章。模型结构如下:
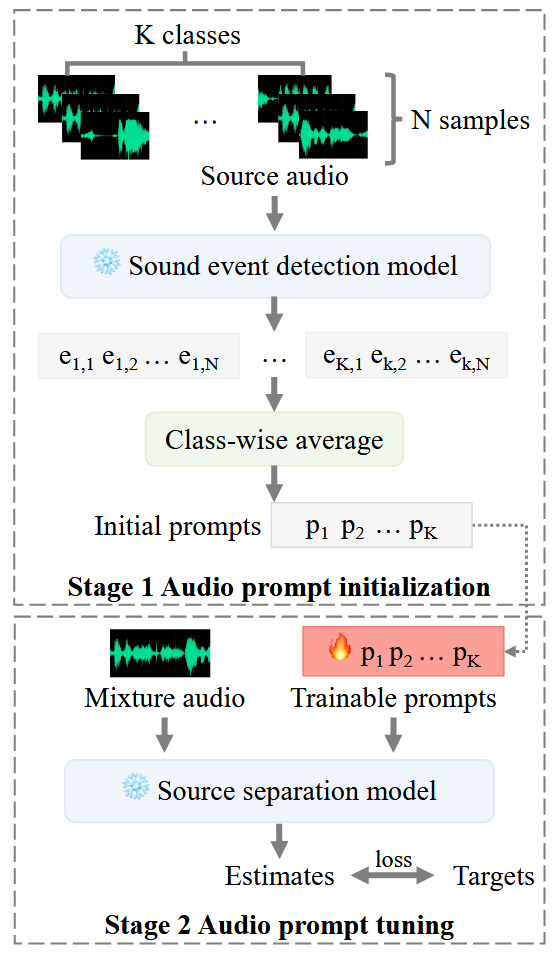
简单来说,作者通过SED模型得到若干类别音频的表示p,然后使用这个p作为prompt来引导模型在混合音频中分离出接近p的音频,这个过程中,SED模型和USS模型参数都是冻结的,只调整p,也就是想找到针对每个类别的音频的合适的prompt,用这个prompt来引导USS模型分离出清晰音频。

Yelfen
这是一篇利用prompt思路优化USS(通用音频分离)任务的文章。模型结构如下:
简单来说,作者通过SED模型得到若干类别音频的表示p,然后使用这个p作为prompt来引导模型在混合音频中分离出接近p的音频,这个过程中,SED模型和USS模型参数都是冻结的,只调整p,也就是想找到针对每个类别的音频的合适的prompt,用这个prompt来引导USS模型分离出清晰音频。
[论文简记]AUDIO PROMPT TUNING FOR UNIVERSAL SOUND SEPARATION
http://www.yelfen.com/archives/lun-wen-jian-ji-audio-prompt-tuning-for-universal-sound-separation