
ATST建立在对比学习之上,了解ATST需要先知道一个音频自监督对比学习模型BYOL-A。
在SSL对比学习中,最大化对比学习中的“正对”相似度,在学习表征方面很有效,但是有时会发生模型崩塌,即模型学不到有意义的表示,而是找到了一种简单但无效的方式来最小化损失函数。COLA模型利用从正样本中区分负样本来解决模型崩塌,但对音频而言,随机取的所谓“负样本”,可能其实与正样本相似,所以BYOL-A模型只用正样本,同时可以克服模型崩溃。BYOL-A使用教师学生模型,教师通过EMA学生网络参数来更新,较为稳定(不易崩塌),学生去预测匹配教师的网络表示。(当然,SSL模型还有另一个技术路线就是随即遮盖预测表示,或者类似于BEATs离散标签分类)
音频的SSL模型使用transformer很少,只有SSAST等,并且它们沿用wav2vec2的思路。(wav2vec2:输入原始音频1维振幅序列然后通过对比学习训练模型)。ATST改进BYOL-A,第一点,使用transformer替代cnn,第二点,使用两个不同的长段来构建正样本,正对的选取是有讲究的,使用audioset进行预训练。
来看模型结构:
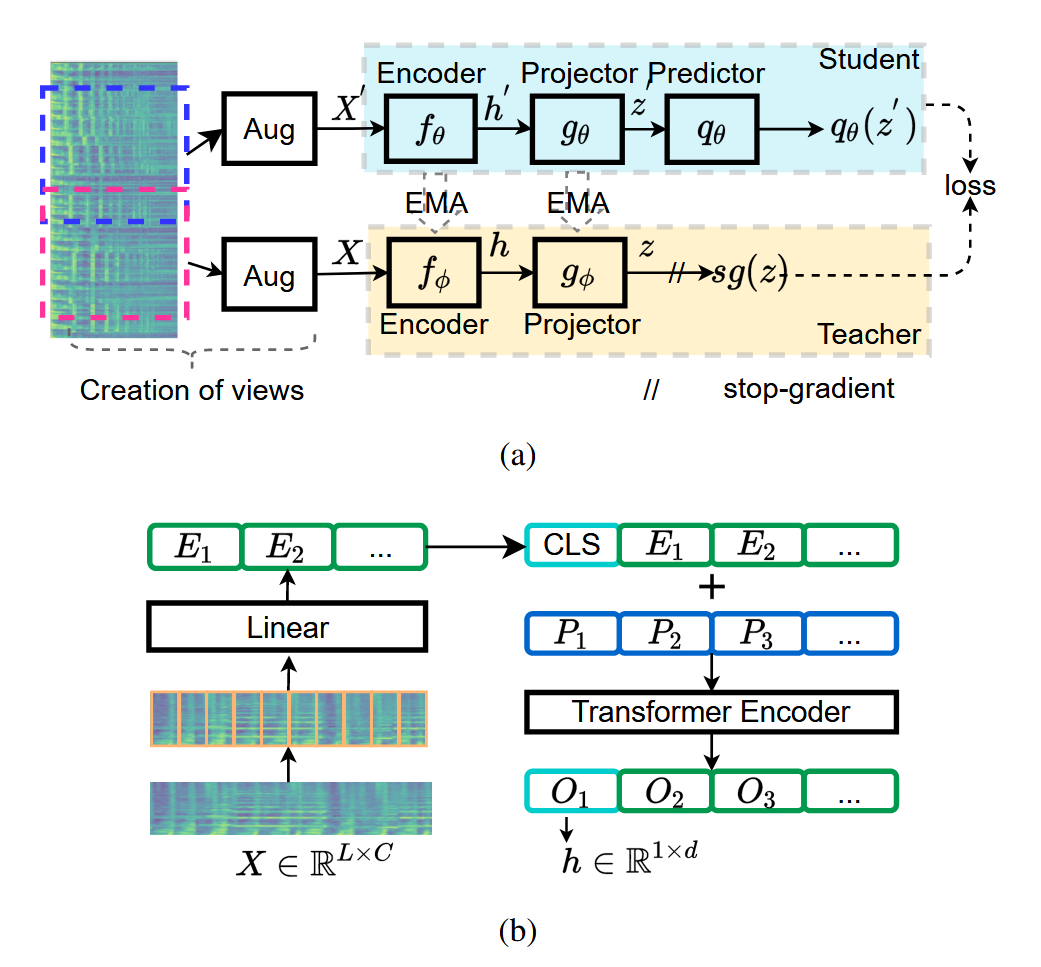
首先将两端略有重合的音频数据分别经过不同的增强得到一个正对,分别输入到学生和教师模型中,然后过encoder和投影器,学生模型去预测教师模型的输出。这个过程是对称的,即X输入到teacher,X’输入到student计算出一个loss,然后交换X和X'再次输入网络得到loss,两个loss加在一起,更新student,注意这个地方teacher并不需要计算梯度,teacher的更新方式是使用ema从学生更新。
Creation of Views
取两个相邻且部分重叠的6秒片段构建正对样本,并且每个片段使用不同的数据增强方法。输入的是mel图。
Transformer Encoder
可以从(b)图中得知,四个帧一组输入linear得到一个embedding,插入一个CLS表示全局信息,CLS是随机初始化,可训练的,再与位置编码结合,得到输出,其中O1来自于CLS,O1作为接下来的h,也就是(a)中编码器的输出